What is GPT? I remember the first time I genuinely asked myself that question. It wasn’t while reading a tech news headline; it was when a friend, a novelist battling writer’s block, told me she was using “this GPT thing” to brainstorm character dialogues. Her eyes weren’t filled with fear of being replaced, but with the spark of a collaborator. That moment shifted my perspective from seeing it as just another tech buzzword to understanding it as a fundamental shift in how we interact with information and creativity. So, let’s demystify it.
In this deep dive, we’ll move beyond the surface. We’ll explore not just what GPT is technically, but how it feels to use it, why it sometimes gets things brilliantly right and hilariously wrong, and what this technology means for our future. I honestly wish I had learned this earlier—not just the technical specs, but the philosophy of a tool that mirrors our own language back at us in such a profound way.
What is GPT, Really? More Than Just a Chatbot
The acronym is your first clue: GPT stands for Generative Pre-trained Transformer. Let’s break that down with a story. Imagine you’ve given a voracious reader access to a significant chunk of the internet—books, articles, websites, code repositories. You don’t give them a specific task like “summarize this” or “translate that.” You simply tell them:
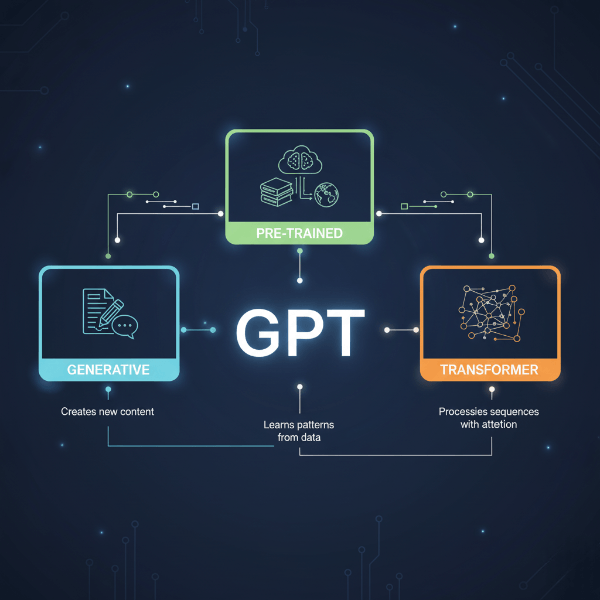
“Read all of this and learn the patterns.” That’s the Pre-trained part. The reader isn’t memorizing facts, but absorbing the relationship between words, ideas, and contexts.
Now, you ask this reader to write a poem, debug a code snippet, or plan a meal for a vegan dinner party. They generate new text based on all those patterns they’ve learned. That’s the Generative part. They’re not copying; they’re composing. Finally, the Transformer is the specific, brilliant architectural design of its “brain” (neural network) that allows it to weigh the importance of every word in a sentence relative to all others, understanding context with remarkable nuance. So, when you ask what is GPT, you’re asking about a deeply pattern-aware, generative language model.
The Engine Room: How Does GPT Actually Work?
This is where most explanations get overly technical, so let me use an analogy from my own life. I play guitar, and learning a new song isn’t about memorizing every single note in sequence. It’s about recognizing chord progressions (the I-IV-V in blues), scales, and rhythms. Once you know these patterns, you can improvise. You can even write a new song that feels like the blues without directly copying B.B. King.

GPT works on a similar principle of pattern recognition and prediction. Its core function is stunningly simple to state and complex in execution: given a sequence of words, predict the next most probable word. Then, take that new sequence and predict the next word again. Repeat.
This process is powered by its Transformer architecture, which uses a mechanism called “attention.” Think of you reading this sentence. You don’t give equal weight to every word you’ve already read; your brain automatically focuses on the key nouns and verbs to maintain context. GPT’s attention mechanism does this mathematically, deciding which words in your prompt (and in its own growing response) are most relevant to the task at hand.
- It processes your input (the prompt).
- It analyzes the relationships between all the words using its pre-trained knowledge.
- It calculates probabilities for what word should come next, based on those trillions of learned patterns.
- It outputs the word with the highest probability (or samples creatively from the top choices).
- It feeds this new sequence back into itself and repeats.
This is why GPT can write a Shakespearean sonnet about your commute or explain quantum physics in the style of a pirate. It’s not “thinking” about pirates or physics; it’s executing a mathematically sophisticated pattern-matching dance.
The Training Journey: How GPT Gets Its "Knowledge"
Understanding what is GPT requires knowing how it’s built. The training happens in broad, distinct phases, much like education.
Phase 1: Unsupervised Pre-training (The "Reading" Phase)
Here, the model is fed a colossal, diverse dataset of text—think petabytes of data from books, the open web, and scientific papers. It has no specific instructions other than to learn the structure of language. During this phase, it develops its fundamental ability to understand grammar, facts about the world (though not always accurately), reasoning styles, and even some biases present in its training data. It’s building its world model from the text alone.
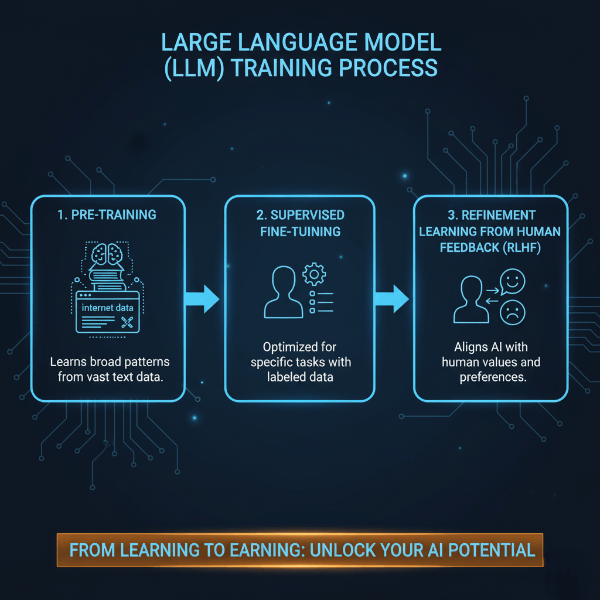
Phase 2: Supervised Fine-Tuning (The "Apprenticeship" Phase)
This is where humans start to guide the model. Labelers (people) provide examples of high-quality prompts and desired responses. For example: “Prompt: Explain the moon’s phases to a child. Response: Imagine the moon is a ball, and the sun is a flashlight…” By training on thousands of these curated examples, GPT learns to align its responses better with human intent—to be helpful, harmless, and honest.
Phase 3: Reinforcement Learning from Human Feedback (RLHF - The "Refinement" Phase)
This is the secret sauce for modern GPT models like ChatGPT. The model generates several responses to a prompt. Human labelers rank these responses from best to worst. Another model learns to predict these human preferences, creating a “reward model.” The main GPT model is then fine-tuned using this reward model to produce responses that humans are likely to prefer. It’s learning through a form of digital reinforcement, constantly nudging it toward more useful and coherent outputs.
YouTube Video: Best Guide on What is GPT and How Does It Work?
Watch this helpful video:
This video from AI Explained provides a fantastic visual breakdown of the Transformer architecture, making the technical concepts much easier to grasp.
The Transformer Architecture: The "Brain" Behind GPT
To truly grasp what is GPT, you need a basic understanding of its core invention: the Transformer. Before 2017, other architectures like Recurrent Neural Networks (RNNs) processed text word by word in sequence, which was slow and made it hard to remember long-range dependencies.
The Transformer changed everything. Its key innovation is the self-attention mechanism. Imagine you’re trying to understand the meaning of the word “it” in a long paragraph. A Transformer can look at every other word in the paragraph simultaneously to decide what “it” refers to. It assigns an “attention score” to each word, determining its relevance.
- Parallel Processing: It processes all words in a sentence at once, making it incredibly efficient for training on massive datasets.
- Context Understanding: This parallel view allows it to build a rich, contextual understanding of the entire input, which is why GPT models are so good at maintaining coherence over long conversations or documents.
According to the seminal paper “Attention Is All You Need” by Vaswani et al., this architecture dramatically improved performance and efficiency, becoming the foundation for not just GPT, but almost every major AI language model since.
From GPT-1 to GPT-4: The Evolution of a Revolution
The journey of what is GPT has become is a story of exponential scaling. Each iteration wasn’t just a minor upgrade; it was a leap in capability, primarily driven by more data, more parameters (the “knobs” in the neural network), and architectural refinements.
- GPT-1 (2018): The proof of concept. It showed that a generative, pre-trained transformer could work for various language tasks with minimal task-specific tweaking.
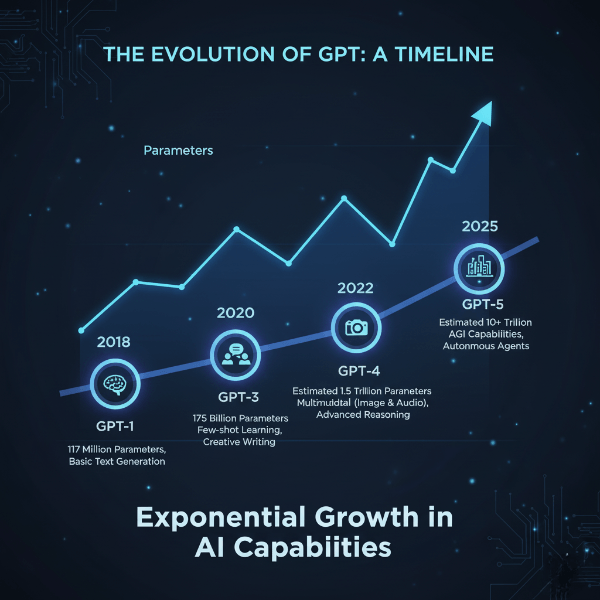
- GPT-2 (2019): A significant scale-up. With 1.5 billion parameters, its text generation was coherent enough to raise concerns about potential misuse, leading to its staged release. It showed the world the creative potential of this technology.
- GPT-3 (2020): The breakthrough. With a staggering 175 billion parameters, it demonstrated few-shot and zero-shot learning—you could give it a task with just a few examples (or even just an instruction), and it could perform it. This made APIs like those from OpenAI and others incredibly powerful and accessible.
- GPT-4 (2023+): The multimodal frontier. While details are closely held, GPT-4 is not only larger but also accepts both text and image inputs (multimodal). It exhibits markedly improved reasoning, accuracy, and steerability. It’s less of a pure language model and more of a reasoning engine. You can learn more about its capabilities in our guide on the latest AI tools.
Each step answered the question “What is GPT?” with a more powerful and astonishing capability.
Practical Magic: Real-World Applications of GPT
So, what is GPT for? It’s moved far beyond parlor tricks. Here’s how it’s being used in the real world, based on my own observations and industry trends:
- Content Creation & Ideation: Writers use it to overcome blank-page syndrome, generate marketing copy variants, or brainstorm blog outlines (much like this one!).

- Programming Assistant: Tools like GitHub Copilot, powered by a GPT-like model, suggest entire lines or blocks of code, turning a programmer’s comment into functional syntax.
- Personalized Tutoring: It can explain complex topics at any requested level of detail, acting as an infinitely patient study partner.
- Business Intelligence: It can summarize long reports, extract key action items from meeting transcripts, and draft professional communications.
- Creative Exploration: Game developers use it to generate dialogue trees, and marketers use it to create multiple ad campaign angles in seconds.
The Limits and Ethical Shadows: What GPT Is Not
It’s crucial to understand the boundaries. When someone asks what is GPT, we must also clarify what it is not.
GPT is not conscious, sentient, or understanding. It simulates understanding through statistical correlation. It has no beliefs, desires, or experiences.

I recall a user sharing a heartfelt conversation with a chatbot, only to be jarred when it later contradicted itself with equal confidence. That emotional whiplash is a reminder: you are interacting with a reflection, not a mind.
It can “hallucinate.” This is the term for when GPT generates plausible-sounding but incorrect or fabricated information. It’s confident because it’s generating based on patterns, not accessing a ground-truth database. Always fact-check its outputs, especially for critical information.
It reflects and can amplify biases. Since it’s trained on human data, it inherits human biases—cultural, gender, racial. Developers use techniques like RLHF to mitigate this, but it remains a critical, ongoing challenge.
Looking Ahead: The Future Shaped by GPT
What is GPT pointing us toward? We’re heading toward more specialized, efficient, and multimodal models. The future likely holds:
- Specialized GPTs: Models fine-tuned for specific domains like law, medicine, or engineering, offering deeper accuracy.
- Multimodal as Standard: Models that seamlessly blend text, image, audio, and video generation and understanding.
- Increased Efficiency: Finding ways to get GPT-level performance with smaller, faster, cheaper models.
- Agentic Behavior: Models that can autonomously take actions based on goals, like booking flights or conducting research, not just generating text.
A recent Forbes article highlighted that the integration of AI like GPT into business workflows is becoming a core competitive strategy, not just an IT experiment.
Conclusion: A Tool for Human Amplification
So, what is GPT? It is arguably the most impactful tool for thought and creation since the internet itself. It’s a mirror of our collective knowledge and a paintbrush for our ideas. Its power lies not in replacing human intelligence, but in augmenting it—freeing us from the friction of starting from zero so we can focus on refinement, strategy, and true innovation.
What’s the most surprising or effective way you’ve used or seen GPT used? Have you had a moment where it felt more like a partner than a tool? I’d love to hear your stories in the comments. And if you’re curious about the next step, try asking a GPT-powered assistant to explain its own architecture back to you—the results can be wonderfully meta.
FAQs About GPT
- What does GPT stand for?
GPT stands for Generative Pre-trained Transformer. It’s a type of AI model designed to generate human-like text by predicting the next word in a sequence based on its training on massive datasets. - How does GPT work?
Think of it like an incredibly advanced version of your phone’s autocomplete. It analyzes the words in your prompt, references the patterns it learned from billions of text examples, and calculates the most probable next word. It repeats this process to generate entire sentences, paragraphs, and conversations. - Is GPT the same as “AI”?
No. GPT is a specific type of AI, just like a sports car is a specific type of vehicle. “AI” is the broad field of creating intelligent machines, while GPT is a specialized tool within that field focused on understanding and generating natural language. - Does GPT browse the internet or “know” facts?
Not directly in real-time (unless integrated with a search tool). Its knowledge is a snapshot from its training data, which has a cutoff date. It doesn’t “know” facts like a database; it generates responses based on patterns, which can sometimes lead to incorrect “hallucinations.” - What are the main drawbacks or risks of GPT?
Key concerns include its potential to generate convincing misinformation (“hallucinations”), perpetuate biases present in its training data, and be used for malicious purposes like phishing or spam. It also lacks true understanding or consciousness, operating purely on statistical prediction.